

Spracherkennung steht im Mittelpunkt in diesem interaktiven Tutorial, du lernst, wie du mit Arduino und TensorFlow Lite ein leistungsfähiges Spracherkennungssystem erstellen kannst. In dem Projekt wirst du die Fähigkeit erlangen, Geräte durch einfache Sprachbefehle zu steuern. Stelle dir vor, du könntest mit einem Wort Roboter bewegen, Lichter steuern oder sogar komplexe Abläufe in deinem Smart Home initiieren. Genau das werden wir hier Schritt für Schritt gemeinsam erreichen.
Spracherkennung ist ein faszinierendes Feld der modernen Technologie und gewinnt zunehmend an Bedeutung in unserer digital vernetzten Welt. Mit diesem Projekt bekommst du nicht nur einen praktischen Einblick in die Welt der künstlichen Intelligenz und des maschinellen Lernens, sondern auch die Gelegenheit, direkt an der Schnittstelle von Hardware und Software zu arbeiten.
Wir starten mit der Auswahl der geeigneten Hardware, dem Arduino Nano 33 BLE Sense und dem Arduino Nicla Vision, und werden dann die Welt der Software mit TensorFlow Lite erkunden. Dabei lernst du, wie man ein neuronales Netzwerk trainiert und anpasst, um verschiedene Sprachbefehle präzise zu erkennen und zu verarbeiten.
Das Ziel dieses Tutorials ist es, dir nicht nur theoretisches Wissen zu vermitteln, sondern dir auch praktische Erfahrungen zu bieten, die du für deine eigenen Projekte nutzen kannst. Du wirst überrascht sein, wie schnell du von den Grundlagen zur Entwicklung deines eigenen Spracherkennungsmodells gelangst.
Bereit für dieses Abenteuer in der Welt der Spracherkennung mit Arduino und TensorFlow Lite? Dann lass uns loslegen und die Magie der Sprachsteuerung gemeinsam entdecken!
Praktische Anwendungsbeispiele:
Bevor wir tiefer in die technischen Details eintauchen, lass uns einige inspirierende Anwendungsmöglichkeiten betrachten:
- Smart Home Steuerung: Sprachgesteuerte Licht- und Heizungsregelung.
- Interaktives Spielzeug: Sprachbefehl-gesteuertes Spielzeugauto.
- Persönlicher Assistent: Sprachgesteuerte Erinnerungen und Wecker.
- Sprachnotizen: Erfassen und Speichern von Notizen über Sprachbefehle.
- Kunstinstallationen: Interaktive Werke, die auf bestimmte Schlüsselwörter reagieren.
Diese Beispiele zeigen, wie vielseitig das Projekt umgesetzt werden kann. Jetzt, da du eine Vorstellung hast, was möglich ist, lass uns mit dem Projekt beginnen.
Was brauchst du für das Projekt Spracherkennung?
Hardware:
Arduino Nicla Version
Software:
Kernziel des Tutorials: Sprachbefehle mit einem maßgeschneiderten Modell erkennen
In diesem Tutorial soll es um den Prozess gehen, wie man ein Spracherkennungsmodell trainiert und nutzt, um verschiedene kurze Sprachbefehle zu identifizieren. Dazu trainieren wir das Sprachmodell auf verschiedene Befehle, wie “down”, “go”, “left”, “no”, “right”, “stop”, “up”, “yes” und usw. All diese sind in tausendfacher Aussprache in kurzen Audio Dateien gespeichert, welche unseren Datensatz ergeben.
Beim Trainieren dieses Sprachmodells gibt es nun zwei mögliche Herangehensweisen:
Eine SaaS-basierte Lösungen wie Edge Impuls Studio
Google Collab mit dem offiziellen TensorFlow Training Ablauf
Beide dieser Methoden zum Trainieren des Sprachmodells haben ihre Vor- und Nachteile. Edge Studio bietet eine benutzerfreundliche Oberfläche und übernimmt bereits viel Arbeit hinter den Szenen. Dies beinhaltet auch die automatische Verarbeitung des Datensatzes und das Trainieren neuer Merkmale. Das heißt es sind nur geringfügige Kenntnisse im Programmieren nötig. Auf der anderen Seite, bei der manuellen Konfiguration mit dem offiziellen Arbeitsablauf können diese Parameter besser, nach dem eigenen Ermessen, angepasst werden. So steht mehr Kontrolle und Konfiguration über das Sprachmodell zu Verfügung.
Erstellen und Trainieren eines Sprachmodells mit Edge Impulse
Edge Impuls ist ein web basierte Anwendung mit dem schnell und einfach verschiedene KI Modelle auf Datensätzen trainiert werden können. Hierzu brauchen Nutzer nicht mehr als die Website in einem Browser zu öffnen und loszulegen.
1. Datensatz herunterladen:
Das wichtigste am Anfang ist die Vorbereitung eines passenden Datensatzes auf dem die KI später trainiert wird. In diesem Projekt benutzten wir ein öffentlichen Datensatz von Google’s TensorFlow Datenbank. Dieser umfasst verschiedene Wave Dateien, welche alle eine Sekunde lang oder kürzer sind.
Der Datensatz kann bei Tensorflow heruntergeladen werden.
Der Datensatz umfasst insgesamt 65.000 dieser Audiodateien mit jeweils einer Sekunde länge. Jeder dieser umfasst 30 verschiedene Wörter, die von tausenden verschiedenen Menschen gesprochen wurden.
2. Projekt erstellen:
Erstelle nun ein neues Projekt mit dem Namen “Erkennung von kurzen Sprachbefehlen mit TensorFlow” Und Lade die entsprechenden Wave Dateien für die verschiedenen Befehle hoch, auf die du das Modell trainieren möchtest.
Für das Tutorial habe 300 Audiodateien für jeden Befehl hochgeladen. Ich habe diese auf fünf begrenzt: “backward”, “forward”, “left”, “right” und “noise” für die vier verschiedenen Richtungen. Jetzt wo du alle Befehle und die entsprechenden Trainingsdaten hochgeladen hast, können wir das Training vorbereiten.
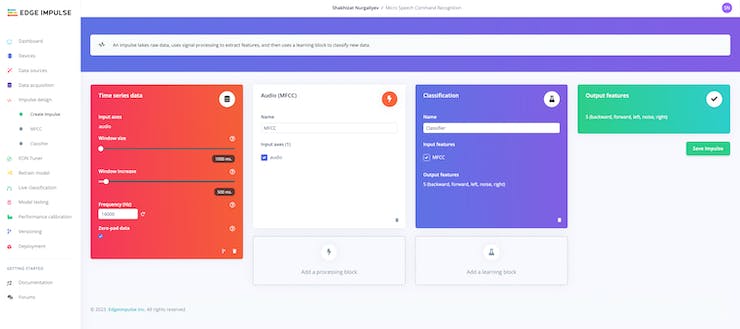
3.Training Vorbereiten:
Navigiere jetzt zu “Impulse Design” auf der linken Seite im Navigationsmenü, um die entsprechenden Einstellungen vorzunehmen. Als erstes erstellen wir ein “processing block” mit “Add a processing block” und wählen MFCC aus. MFCC steht für “Mel Frequency Cepstral Coefficients” und ist eine Methode die Audiodateien in verschiedene Merkmale zu kategorisieren. Anhand dieser können die einzelnen Audiodaten, dann klassifiziert werden. Klicke jetzt noch “Save Impulse” zum Speichern.
Navigiere jetzt zu “MFCC”. Die Merkmals-Extraktion beschreibt den Prozess bei dem eine Gruppe an Werten gefunden wird, um bestimmte Objekte zu beschreiben und zu identifizieren. MFCC wird daher häufig in solchen Szenarien, wo es um Spracherkennung geht angewandt.
Klick jetzt “Save parameters” und dann “Generate Features”
Als nächstes klicke “Classifier” in der Navigationsleiste. Hier wollen wir jetzt die KI für 100 Epochen mit einer Trainingsrate von 0.005 trainieren. Klicke “Start” um den Prozess zu starten. Dieser Prozess kann einige Zeit in Anspruch nehmen, abhängig von der große des gewählten Datensatzes und Anzahl der Epochen. Während das Training läuft sollte der Fortschritte graphisch angezeigt werden.
Sobald der Prozess abgeschlossen ist, solltest du ein ähnliches Resultat wie im folgenden Screenshot sehen:
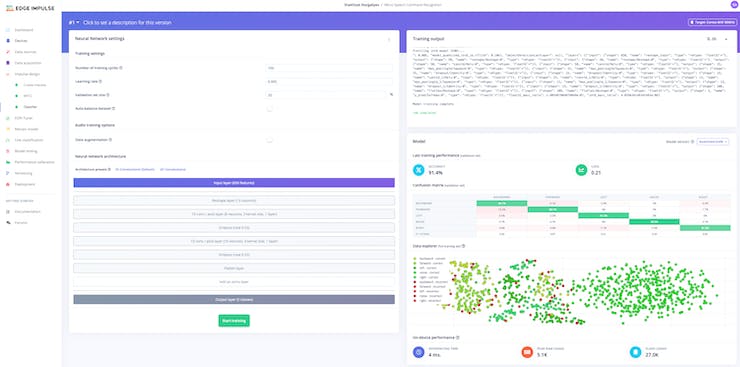
4. Testen & Deploy
In meinem Fall habe ich eine Präzision von 91.4% beim Testen mit dem Model bei noch unbekannten Audiodateien. Durch erhöhen der Epochen könnte diese Nummer z.B. noch erhöht werden. Das Endergebnis des Models ist, dann in einer Datei mit ca. 6KB in Größe gespeichert.
Jetzt kannst du das Sprachmodell eigenen Stimme ausprobieren. Navigiere hierfür zu “Deployment” und wähle in unserem Fall “Arduino Library” aus. Jetzt sollte eine .zip Datei heruntergeladen werden mit der Library. Extrahiere den Inhalt und öffne ihn nun mit der Arduino IDE.

Zum Starten öffne die Datei “nano_ble33_sense_microphone_continuous.ino” mit der Arduino IDE. Kompiliere jetzt den Quelltext und lade diesen auf das Arduino Nano 33 BLE Board. Außerdem verifiziere , dass die “build rate” (Baurate) auf 115200 gesetzt ist. Sollte alles richtig eingerichtet sein müsste ein ähnliches Ergebnis wie hier vorliegen:
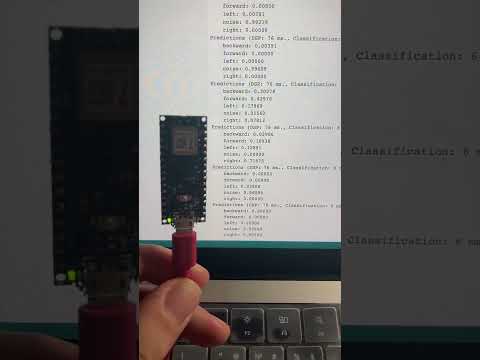
Starte den Prozess durch das Aussprechen einer der Befehle. Das Spracherkennungsmodell haben wir in der Cloud trainiert mithilfe von Edge Impulse. Können jetzt aber auch dieses lokal auf dem Arduino Board laufen lassen und für verschiedene Projekte benutzen.
Erstellen und Trainieren eines Sprachmodells mit Google Colab
In diesem Abschnitt befassen wir uns nun mit der zweiten Methode. Nach beenden des Trainings, testen wir die Ergebnisse mit dem Arduino Nicla Vision mit der OpenMV IDE.

1. Kompatibität testen:
Um die Kompatibilität mit TensorFlow 2.x sicherzustellen wurden ein paar Anpassungen an dem Notebook vorgenommen. Folge daher einfach den gegebenen Anweisungen im Notebook “https://colab.research.google.com/drive/1XLJn811UB0yBYip6J2Qt45DJLaCsoQKR#scrollTo=ludfxbNIaegy” und führe die einzelnen Schritte mit “Run” aus. Beachte dabei, dass es wichtig ist immer zu warten bis der vorherige Schritt beendet ist.
2. Trainingszyklus starten:
Sobald TensorFlow mit dem kompilieren fertig ist, startet der Trainingszyklus. Dieser kann wie bei Edge Impulse bis zu zwei Stunden dauern. Nach dem Beenden sollte die Präzision der Spracherkennung, die Größe eines Sprachmodell in Gleitkommazahlen und die eines quantisiertes Sprachmodell angezeigt werden. Die Quantisierung beschreibt hierbei eine Technik bei der die Präzision von Gewichten im Neuronalen Netzwerk verändert, um die Komplexität vom Sprachmodell zu reduzieren. Diese können dann effizienter und schnell auf eingebetteten Systemen wie diesen ausgeführt werden.


Dies erkennt man sofort, da das Modell mit Gleitkommazahlen relativ groß ist mit 68 356 Bytes., während das quantisierte Modell nur 18 960 Bytes groß ist. Somit also ein deutlicher Größenunterschied zwischen den beiden Modellen besteht.


3. Test für Präzision vom TensorFlow Lite Modell :
Für den Test wurden 1212 neue Audiodateien verwendet. Diese hat das Sprachmodell noch nicht zuvor gehört und dann anhand des vorherigen Trainings klassifiziert.
Das Modell mit den Gleitzahlen hatte dabei eine Präzision von 91,254125% und das quantisierte Modell hatte eine Präzision von 91,336634%. Damit ist die Präzision vom quantisierten Modell sogar höher und weißt darauf hin, dass die Quantisierung unser Modell nicht bemerkbar verschlechtert hat. So kann die “verkleinerte” Version besser und effizienter auf eingebetteten System mit weniger Rechenleistung ausgeführt werden.
Für eine visuelle Veranschaulichung des Modells kannst du netron.app benutzten. Netron ist eine Oberfläche zur grafischen Darstellung von neuronalen Netzwerken wie diesem. So können ohne Probleme die einzelnen Schichten des Modells und der Aufbau des Netzwerkes angeschaut werden. Auch die einzelnen “weights” und “biases” können eingesehen werden für verschiedene Schichten.

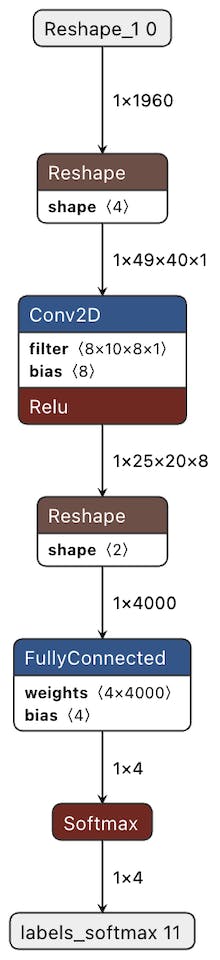
Der “Reshape Layer” ist verantwortlich die Eingangsdaten umzuwandeln, sodass die den Maßen für den “Convolution Layer” entsprechen. “Conv2D” extrahiert dann aus den ungeformten Daten verschiedene Merkmale. Die letzte Schicht “FullyConnected” ist über einzelne Neuronen vollständig mit dem letzten “Output Layer” (der Ausgabe Schicht) verbunden. Den Daten in der Neuronen Menge werden, dann über eine Funktion namens “Softmax” eine Wahrscheinlichkeit zugeordnet. Diese gibt an für wie wahrscheinlich es sich um ein bestimmtes Wort handelt. So konnten wir dies in der vorherigen Demo bereits beobachten. Es wurden immer 5 Zahlen ausgegeben, welche die Wahrscheinlichkeit für die einzelnen Wörter anzeigt.
4. Quantisierte Modell Downloaden und OpenMV installieren:
Damit wir jetzt das quantisierte Modell auf dem Arduino Nicla Vision ausprobieren können, lade es wie im folgenden Bild dargestellt herunter.
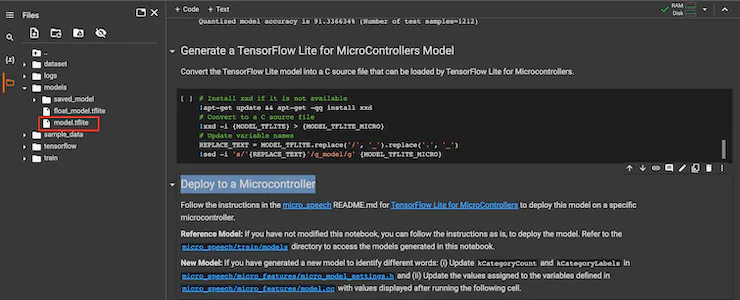
Weitere Anweisungen findest du sonst auch ganz unten im Notebook auf Google Colab.
Installiere jetzt OpenMV für dein System falls du das noch nicht getan hast und öffne die Anwendung.
Kopiere und füge den nachfolgenden Quelltext dann einfach in die OpenMV IDE ein.
import audio, time, tf, micro_speech, pyb
<br>labels = ['Silence', 'Unknown', 'Right', 'Left']
<br>model = tf.load('/model.tflite')
<br>speech = micro_speech.MicroSpeech()
<br>audio.init(channels=1, frequency=16000, gain=24, highpass=0.9883)
<br>
<br># Start audio streaming
<br>audio.start_streaming(speech.audio_callback)
<br>
<br>while (True):
<br># Run micro-speech without a timeout and filter detections by label index.
<br> idx = speech.listen(model, timeout=0, threshold = 0.78)
<br> print(labels[idx])
<br>
<br># Stop streaming
<br>audio.stop_streaming()
<br>
<br>
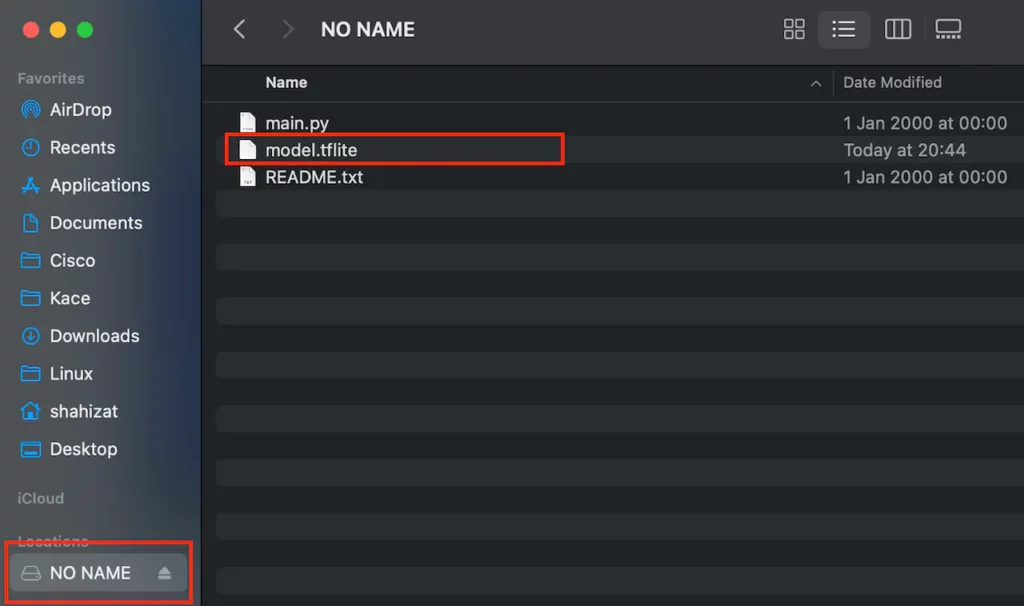
<br>5. Sprachmodel auf Arduino Nicla übertragen:
Übertrage nun das heruntergeladende Sprachmodell auf den Arduino Nicla mit deinem Dateiexplorer. Der Arduino sollte dort als externes Speichergerät aufgeführt werden. Kopiere die Datei wie im Bild, dann einfach über “Drag & Drop” auf den Arduino.
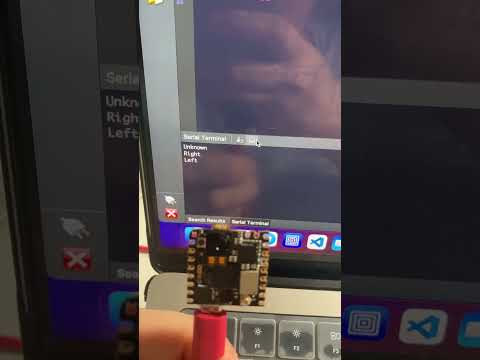
Zum Ausführen des Programm klicke den “Playbutton” links unten in der Ecke und öffne den Seriellen Monitor. Dort sollten dann die erkannten Befehle ausgegeben werden.
Fazit
Ich habe eine umfassende Anleitung zur Schulung eines einfachen Audioerkennungsmodells mit dem Google Colab-Notizbuch bereitgestellt, das spezifische Schlüsselwörter in der Sprache mit nur 20 kB Daten genau identifizieren kann. Dieses Tutorial ist eine wertvolle Ressource für jeden, der sich für Audioerkennung und maschinelles Lernen mit Arduino-Boards interessiert.
Auch wenn das Modell relativ simpel war hat man einen ersten guten Überblick über Neuronale Netzwerke in Verbindung mit dem Arduino bekommen. Von hier an kannst du jetzt dein Wissen mit neuen und komplexeren Herausforderungen erweitern. Daher hoffe ich, dass ich Interesse mit der Arbeit solcher Neuronalen Netzwerken bei der Spracherkennung in dir wecken konnte.
Shakhizat Nurgaliyev
Wir sind begeistert, dir heute einen spannenden Artikel präsentieren zu können, der uns von Shakhizat Nurgaliyev zur Verfügung gestellt wurde. Shakhizat ist ein leidenschaftlicher Entwicklungsingenieur für eingebettete Systeme mit einer beeindruckenden Expertise in den Bereichen Robotik und Internet der Dinge (IoT). Seine Spezialisierung liegt in der Entwicklung autonomer und intelligenter Systeme, die maschinelles Lernen nutzen, um auf ihre Umgebung zu reagieren. Von der Konzeption bis zur Programmierung bringt er umfangreiche Erfahrung mit, die maßgeblich zur Weiterentwicklung von Robotik und IoT beiträgt.