

Hast du schon einmal daran gedacht, einen Heim-Speichercluster mit Raspberry Pi und Ceph einzurichten, stießt aber auf Fragen bezüglich der Umsetzung? Unser aktueller Blogpost liefert die Lösung. Er begleitet dich Schritt für Schritt durch den Prozess, um eine solide und erweiterbare Speicherlösung selbst zu realisieren.
- Verwendete Materialien in diesem Projekt
- Was ist Ceph?
- Kernkomponenten von Ceph
- Aufbau eines Ceph-Clusters mit Raspberry Pi
- Voraussetzungen für die Ceph-Bereitstellung
- Bereitstellung eines Ceph-Speicherclusters mit ceph-deploy
- Verwaltung und Überwachung des Clusters
- Mount CephFS mit Kernel Driver
- Starten und Stoppen aller Daemons
- Fazit und Ausblick
- Shakhizat Nurgaliyev
Verwendete Materialien in diesem Projekt
Hardware-Komponenten:
- Raspberry Pi 5 8GB: 3 Stück – Diese kraftvollen kleinen Computer bilden das Herzstück unseres Ceph-Clusters. Mit 8 GB RAM ausgestattet, sind sie perfekt für anspruchsvolle Aufgaben und bieten genug Leistung für unser Speichernetzwerk.
Software-Apps und Online-Dienste:
- balenaEtcher: Ein unverzichtbares Tool, um unsere Betriebssystem-Images sicher und zuverlässig auf die SD-Karten für unsere Raspberry Pis zu flashen. Einfach zu nutzen und absolut zuverlässig.
- Ceph: Die Open-Source-Software-definierte Speicherlösung, die den Kern unseres Projekts ausmacht. Ceph ermöglicht uns die Einrichtung eines skalierbaren und ausfallsicheren Speicherclusters.
Mit dieser Kombination aus leistungsstarker Hardware und vielseitiger Software sind wir bestens ausgestattet, um unseren eigenen Heim-Speichercluster aufzubauen. Die Einrichtung ist dank der benutzerfreundlichen Tools und der robusten Raspberry Pi Hardware nicht nur effizient, sondern auch ein spannendes Projekt für alle Technikbegeisterten.
Was ist Ceph?
Ceph ist eine Open-Source-Software-definierte Speicherplattform, die verteilte Datei-, Block- und Objektspeicherfunktionalitäten bietet. Sie ermöglicht dir die Erstellung eines fehlertoleranten Datenspeichersystems, das über das TCP/IP-Protokoll zugänglich ist.
CephFS ist eine Komponente von Ceph, die eine POSIX-konforme Dateisystem-Schnittstelle bietet. Client-Systeme können den RADOS-Objektspeicher von Ceph mit CephFS mounten, sodass er wie ein Standard-Linux-Dateisystem erscheint. Dies ermöglicht eine Dateifreigabefunktionalität, ähnlich traditionellen Lösungen wie NFS. Ceph-Clients mounten ein CephFS-Dateisystem als Kernel-Objekt oder als Filesystem im User Space (FUSE).
Kernkomponenten von Ceph
MON (Ceph Monitor)
Monitore sind das Gehirn des Ceph-Clusters. Sie verwalten die Gesundheit des Clusters, verfolgen den Zustand der Object Storage Devices und bieten Authentifizierung für Clients und Daemons. Für Redundanz und hohe Verfügbarkeit werden mindestens drei Monitore empfohlen.
OSD (Object Storage Device)
OSDs speichern Daten und verarbeiten Client-Anfragen. Daten innerhalb eines OSD werden geteilt und in Blöcken gespeichert. Ceph OSD Daemons übernehmen Lese-, Schreib- und Replikationsoperationen auf Speicherlaufwerken. Für Redundanz und hohe Verfügbarkeit werden normalerweise mindestens drei Ceph OSDs benötigt. Dies kann eine traditionelle Festplatte (HDD) oder eine Solid-State-Disk (SSD) sein.
MDS (Metadata Server Daemon)
Der MDS spielt eine entscheidende Rolle in CephFS. Er verwaltet die Metadaten, die mit dem Dateisystem verbunden sind, und ermöglicht effiziente Dateioperationen. Der Ceph Metadata Server ist notwendig, um Ceph File System-Clients zu betreiben.
MGR (Manager Daemon):
Ein zentraler Baustein des Ceph-Clusters, der MGR, überwacht und verwaltet alle wesentlichen Betriebsparameter. Von der Speichernutzung bis hin zu Leistungsmetriken gewährleistet der MGR, dass der Cluster stets optimiert und sicher läuft. Für die hohe Verfügbarkeit und Robustheit des Systems spielt der MGR eine entscheidende Rolle
Aufbau eines Ceph-Clusters mit Raspberry Pi
Hier ein Diagramm eines Ceph-Clusters, bestehend aus Raspberry Pi-Knoten.

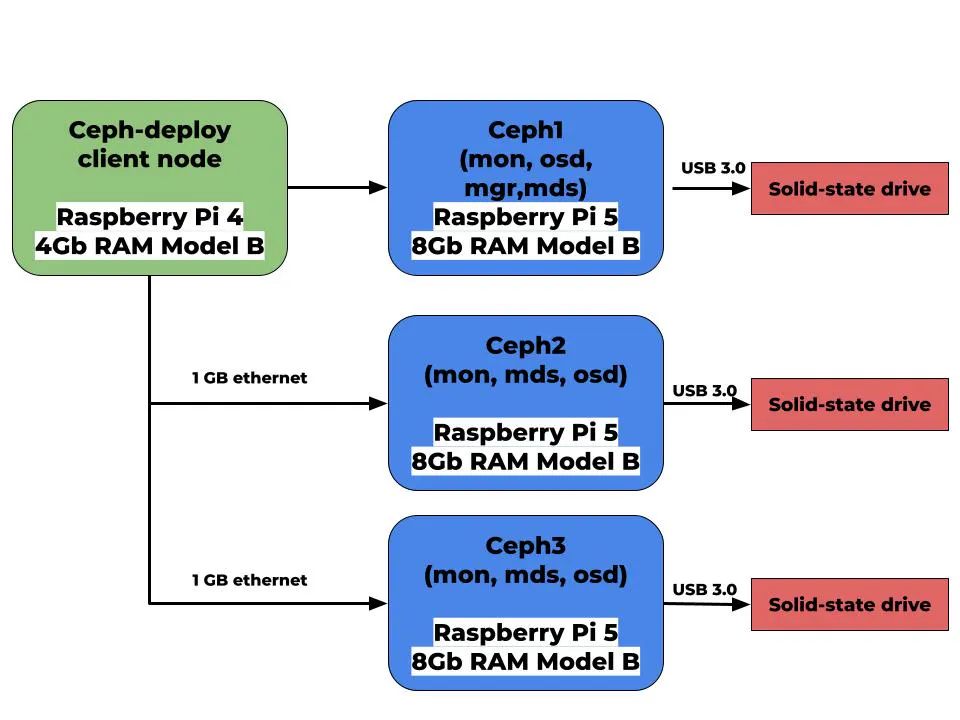
Mein Ceph-Cluster wird aus drei Raspberry Pi 5 bestehen, die über einen 1Gbit-Switch in einem privaten Netzwerk verbunden sein werden. Als Speicher verwende ich drei 256GB Flash-SSD-Laufwerke. Obwohl Solid-State-Laufwerke für eine bessere Leistung empfohlen werden, wird die Gesamtgeschwindigkeit durch die Nutzung von USB 3.0 sowieso begrenzt. Der Raspberry Pi 5 basiert auf dem Betriebssystem Debian 12 (Bookworm), während der Raspberry Pi 4 auf dem Server-Betriebssystem Ubuntu 22.04 basiert.
So sieht mein Ceph-Cluster aus:


In echten Einsatzszenarien haben Ceph-Cluster typischerweise viel mehr OSDs, als auf dem Bild gezeigt wird. Das liegt daran, dass Ceph auf Replikation setzt, um Daten zu schützen. Jedes Objekt wird über mehrere OSDs repliziert. Falls ein OSD ausfällt, können dessen Daten immer noch von den Replikaten abgerufen werden, was Datenredundanz und -verfügbarkeit sicherstellt.
Für weitere Informationen über Ceph kannst du dich auf die offizielle Dokumentation beziehen: Einführung in Ceph.
Voraussetzungen für die Ceph-Bereitstellung
Bevor wir beginnen, ist es wichtig, sicherzustellen, dass alle Knoten im Cluster über korrekt konfigurierte IPs, Netzwerk- und Hostnameneinstellungen verfügen.
Zuerst müssen wir per SSH auf unseren Bereitstellungsknoten zugreifen. Stelle sicher, dass du IPs, Netzwerk und /etc/hosts auf allen Pi-Knoten eingerichtet hast, falls du kein lokales DNS und DHCP mit statischen Zuweisungen verwendest.
Netzwerk- und Hostnamen-Konfiguration
Jeder Ceph-Knoten MUSS in der Lage sein, jeden anderen Ceph-Knoten im Cluster über seinen kurzen Hostnamen anzupingen. Du kannst den Befehl hostnamectl verwenden, um auf jedem Knoten angemessene Hostnamen einzurichten.
hostnamectl set-hostname {your hostname}Alle Ceph-Knoten sollten über den Hostnamen mithilfe der Datei /etc/hosts auf jeder Maschine auflösbar sein. Hier ist ein Beispiel für eine /etc/hosts-Konfiguration für dein Szenario:
192.168.0.100 deployment
192.168.0.106 ceph1
192.168.0.107 ceph2
192.168.0.108 ceph3
Zeit-Synchronisation
Wir müssen auch sicherstellen, dass die Systemuhren nicht verzerrt sind, damit der Ceph-Cluster ordnungsgemäß funktionieren kann. Es wird empfohlen, die Zeit mit einem NTP-Server zu synchronisieren.
Da ceph-deploy nicht nach einem Passwort fragt, musst du SSH-Schlüssel auf dem Bereitstellungsknoten generieren und den öffentlichen Schlüssel an jeden
ssh-copy-id <username>@node1 <br>ssh-copy-id <username>@node2 <br>ssh-copy-id <username>@node3Diese Befehle fügen den öffentlichen Schlüssel des Admin-Knotens zu den Dateien authorized_keys auf jedem Ceph-Knoten hinzu, wodurch passwortloser SSH-Zugang für Bereitstellungsaufgaben ermöglicht wird.
Bereitstellung eines Ceph-Speicherclusters mit ceph-deploy
Dieser Leitfaden beschreibt die Bereitstellung eines Ceph-Speicherclusters unter Verwendung des Tools ceph-deploy. ceph-deploy vereinfacht den Prozess, indem es viele Konfigurationsschritte automatisiert.
Das Raspberry Pi OS mit dem Namen Bookworm wurde zeitgleich mit dem Raspberry Pi 5 veröffentlicht. Folglich wurde es von Debian 11 “Bullseye” auf Debian 12 “Bookworm” aktualisiert. Da die Ceph-Version 18.2.0 (Reef) Debian 12 Bookworm unterstützt, werden wir uns auf die Installation dieser spezifischen Version konzentrieren.
Auf dem Bereitstellungsknoten, der in meinem Fall Raspberry Pi 4 Boards sind, installiere ceph-deploy mit pip:
pip3 install git+https://github.com/ceph/ceph-deploy.gitInitialisierung des Ceph-Clusters
Führe den folgenden Befehl aus, um einen neuen Cluster namens ceph mit Monitoren auf den Knoten ceph1, ceph2 und ceph3 zu erstellen:
ceph-deploy new ceph1 ceph2 ceph3Die Ausgabe zeigt detaillierte Informationen zu jedem Schritt an.
[ceph_deploy.conf][DEBUG ] found configuration file at: /home/raspi/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.1.0): /usr/local/bin/ceph-deploy new ceph1 ceph2 ceph3
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] mon : ['ceph1', 'ceph2', 'ceph3']
[ceph_deploy.cli][INFO ] ssh_copykey : True
[ceph_deploy.cli][INFO ] fsid : None
[ceph_deploy.cli][INFO ] cluster_network : None
[ceph_deploy.cli][INFO ] public_network : None
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf object at 0xffff9315e110>
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.cli][INFO ] func : <function new at 0xffff93481cf0>
[ceph_deploy.new][DEBUG ] Creating new cluster named ceph
[ceph_deploy.new][INFO ] making sure passwordless SSH succeeds
[ceph1][DEBUG ] connected to host: head
[ceph1][INFO ] Running command: ssh -CT -o BatchMode=yes ceph1 true
[ceph1][DEBUG ] connection detected need for sudo
[ceph1][DEBUG ] connected to host: ceph1
[ceph1][INFO ] Running command: sudo /bin/ip link show
[ceph1][INFO ] Running command: sudo /bin/ip addr show
[ceph1][DEBUG ] IP addresses found: ['192.168.0.106']
[ceph_deploy.new][DEBUG ] Resolving host ceph1
[ceph_deploy.new][DEBUG ] Monitor ceph1 at 192.168.0.106
[ceph_deploy.new][INFO ] making sure passwordless SSH succeeds
[ceph2][DEBUG ] connected to host: head
[ceph2][INFO ] Running command: ssh -CT -o BatchMode=yes ceph2 true
[ceph2][DEBUG ] connection detected need for sudo
[ceph2][DEBUG ] connected to host: ceph2
[ceph2][INFO ] Running command: sudo /bin/ip link show
[ceph2][INFO ] Running command: sudo /bin/ip addr show
[ceph2][DEBUG ] IP addresses found: ['10.122.116.1', '192.168.0.107']
[ceph_deploy.new][DEBUG ] Resolving host ceph2
[ceph_deploy.new][DEBUG ] Monitor ceph2 at 192.168.0.107
[ceph_deploy.new][INFO ] making sure passwordless SSH succeeds
[ceph3][DEBUG ] connected to host: head
[ceph3][INFO ] Running command: ssh -CT -o BatchMode=yes ceph3 true
[ceph3][DEBUG ] connection detected need for sudo
[ceph3][DEBUG ] connected to host: ceph3
[ceph3][INFO ] Running command: sudo /bin/ip link show
[ceph3][INFO ] Running command: sudo /bin/ip addr show
[ceph3][DEBUG ] IP addresses found: ['192.168.0.108']
[ceph_deploy.new][DEBUG ] Resolving host ceph3
[ceph_deploy.new][DEBUG ] Monitor ceph3 at 192.168.0.108
[ceph_deploy.new][DEBUG ] Monitor initial members are ['ceph1', 'ceph2', 'ceph3']
[ceph_deploy.new][DEBUG ] Monitor addrs are ['192.168.0.106', '192.168.0.107', '192.168.0.108']
[ceph_deploy.new][DEBUG ] Creating a random mon key...
[ceph_deploy.new][DEBUG ] Writing monitor keyring to ceph.mon.keyring...
[ceph_deploy.new][DEBUG ] Writing initial config to ceph.conf...
Dieser Befehl führt mehrere Aktionen aus:
- Etabliert passwortlosen SSH-Zugang zwischen dem Bereitstellungshost und den Ceph-Knoten.
- Erstellt einen Ceph-Cluster namens ceph mit anfänglichen Monitoren auf ceph1, ceph2 und ceph3.
Der oben genannte Befehl erzeugt eine Datei ceph.conf, die folgendermaßen aussieht:
fsid = 3218618a-ce05-4277-9a0d-325063ce54cc
mon_initial_members = ceph1, ceph2, ceph3
mon_host = 192.168.0.106,192.168.0.107,192.168.0.108
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
Jeder Ceph-Cluster hat seine eigene einzigartige FSID-Identität. Ceph bietet zwei Authentifizierungsmodi an: none (jeder kann ohne Authentifizierung auf Daten zugreifen) oder cephx (schlüsselbasierte Authentifizierung).
Installiere auf allen Ceph-Knoten die notwendigen Ceph-Pakete mit dem Paketmanager deiner Distribution.
sudo apt-get install python3-ceph-argparse=16.2.11+ds-2 python3-ceph-common=16.2.11+ds-2 ceph-mgr-modules-core=16.2.11+ds-2 ceph-mgr=16.2.11+ds-2 python3-cephfs=16.2.11+ds-2Installiere Ceph auf allen Knoten mit ceph-deploy install. Gib nach der Option --release die gewünschte Ceph-Version an (z.B. reef).
ceph-deploy install --release reef ceph1 ceph2 ceph3Verwende ceph-deploy, um die anfänglichen Monitore auf den festgelegten Knoten zu erstellen:
ceph-deploy mon create-initialKopiere die generierte Ceph-Konfigurationsdatei vom Bereitstellungsknoten auf alle Ceph-Knoten:
ceph-deploy admin ceph1 ceph2 ceph3<br>Jetzt lass uns den Status des ersten Clusters überprüfen, indem wir uns per SSH in einen Ceph-Knoten einloggen und den untenstehenden Befehl ausführen, um die Gesundheit des Clusters zu überprüfen.
sudo ceph healthWir können den Status des Clusters auch mit dem folgenden Befehl überprüfen:
sudo ceph -sDiese Ausgabe zeigt den Status von Monitoren, Managern, OSDs und anderen Cluster-Komponenten an.
cluster:
id: 8b7cb3f3-f4b0-4d17-8d08-aaaf0b5030b2
health: HEALTH_WARN
mons are allowing insecure global_id reclaim
services:
mon: 3 daemons, quorum ceph1,ceph2,ceph3 (age 44s)
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
Wenn wir den Status HEALTH_OK erhalten, bedeutet das, dass der Cluster erfolgreich initialisiert wurde. Lass uns zum Bereitstellungsknoten zurückkehren und den Manager-Daemon mit dem folgenden Befehl installieren:
ceph-deploy mgr create ceph1Der Manager-Daemon ist für die grundlegende Speicherfunktionalität nicht unbedingt notwendig, kann aber zusätzliche Funktionen wie Überwachung und Orchestrierung bieten.
Wichtig: Stelle sicher, dass die Ziellaufwerke nicht in Gebrauch sind und keine kritischen Daten enthalten.
Verwende dd, um vorhandene Daten auf den Ziellaufwerken zu löschen (z.B. /dev/sda1):
dd bs=1M count=1 </dev/zero >/dev/sda1Bestätige den Gerätetyp mit dem Befehl file.
sudo file -s /dev/sda1Die Ausgabe sollte “data” anzeigen.
sudo file -s /dev/sda1
/dev/sda1: data
Führe auf dem Bereitstellungsknoten ceph-deploy osd create aus, um OSDs auf den angegebenen Geräten auf jedem Ceph-Knoten zu erstellen (z.B. /dev/sda1).
ceph-deploy osd create --data /dev/sda1 ceph1
ceph-deploy osd create --data /dev/sda1 ceph2
ceph-deploy osd create --data /dev/sda1 ceph3
Ersetze /dev/sda1 durch das tatsächliche Gerät auf jedem Knoten. Du solltest eine Nachricht sehen, die anzeigt, dass jeder Host für die Verwendung von OSD bereit ist.
[ceph_deploy.osd][DEBUG ] Host ceph1 is now ready for osd use.
[ceph_deploy.osd][DEBUG ] Host ceph2 is now ready for osd use.
[ceph_deploy.osd][DEBUG ] Host ceph3 is now ready for osd use.
Überprüfe den Clusters mit ceph status:
cluster:
id: 3218618a-ce05-4277-9a0d-325063ce54cc
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph1,ceph2,ceph3 (age 26m)
mgr: ceph2(active, since 26m), standbys: ceph1
mds: 1/1 daemons up, 2 standby
osd: 3 osds: 3 up (since 26m), 3 in (since 2d)
data:
volumes: 1/1 healthy
pools: 3 pools, 65 pgs
objects: 22 objects, 6.8 KiB
usage: 35 MiB used, 715 GiB / 715 GiB avail
pgs: 65 active+clean
Unser Cluster scheint gesund zu sein, und alle drei Monitore sowie OSDs sind unter den Diensten aufgelistet.
Installiere das Ceph Manager Dashboard-Paket auf dem Knoten, auf dem der Manager läuft:
sudo apt install ceph-mgr-dashboard=16.2.11+ds-2Ersetze die Versionsnummer (16.2.11+ds-2), falls nötig.
Aktiviere das Dashboard-Modul.
sudo ceph mgr module enable dashboardErstelle ein selbstsigniertes Zertifikat für die Authentifizierung:
sudo ceph dashboard create-self-signed-certDie Ausgabe sollte bestätigen: “Selbstsigniertes Zertifikat erstellt.”
Erstelle einen Benutzer für den Dashboard-Zugriff:
sudo ceph dashboard ac-user-create admin -i password administratorBetrachte verfügbare Ceph Manager Dienste:
sudo ceph mgr servicesDie Ausgabe sollte die Dashboard-URL wie folgt anzeigen:
{<br>"dashboard": "https://YOUR_IP_ADDRESS:8443/"<br>}Verwaltung und Überwachung des Clusters
Einrichten des Ceph Manager Dashboards
Das Dashboard bietet einen Überblick über den Gesundheitszustand des Ceph-Clusters und ermöglicht die Verwaltung über eine Web-Oberfläche.
Nach Abschluss der obigen Konfiguration gib https://YOUR_IP_ADRESSE:8443/ in den Browser ein, um den Benutzernamen und das Passwort einzugeben und auf das Ceph-Dashboard zuzugreifen sowie Ihren Ceph-Speichercluster zu verwalten.
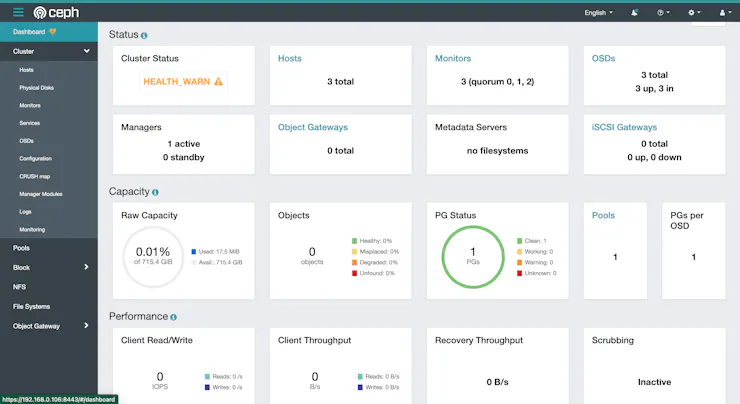
Die Clusteransicht des Ceph-Dashboards bietet dir einen Überblick über den Gesundheitszustand deines Ceph-Clusters, indem sie die verschiedenen Ceph-Daemons, deren Status und deren Ressourcenzuweisung anzeigt.
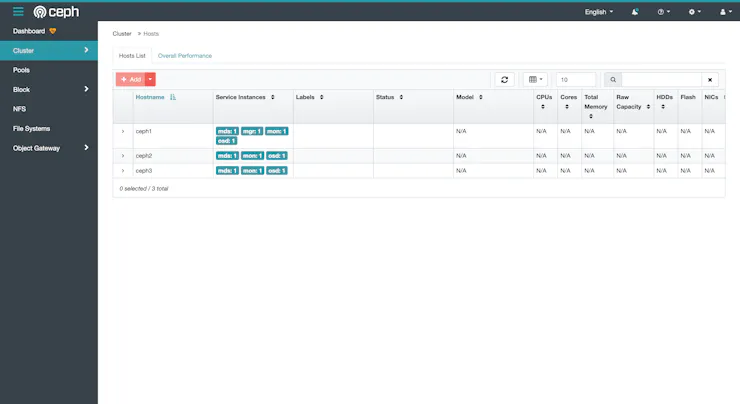
Der Host-Bereich des Dashboards zeigt einen Überblick über die Mitgliedshosts des Ceph-Clusters. Diese Ansicht würde typischerweise Informationen wie den Hostnamen und die aktuelle Rolle jedes Hosts innerhalb der Ceph-Umgebung anzeigen, einschließlich ob sie als OSDs oder andere Rollen wie Metadatenserver dienen.
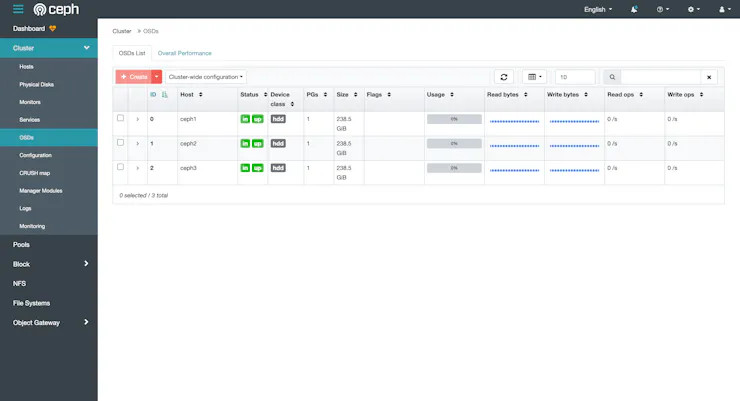
OSDs sind verantwortlich für die Speicherung der tatsächlichen Datenobjekte innerhalb des Ceph-Clusters. Diese Geräte können physische Festplatten oder andere Speichergeräte sein, die mit den Hosts verbunden sind, welche als OSDs dienen.
Anschließend müssen wir den Metadata Server (MDS) für das Ceph-Dateisystem konfigurieren. Wir können ceph-deploy vom Deployment-Host aus verwenden, um MDS auf den Knoten ceph1, ceph2 und ceph3 zu deployen und zu konfigurieren:
ceph-deploy --overwrite-conf mds create ceph1 ceph2 ceph3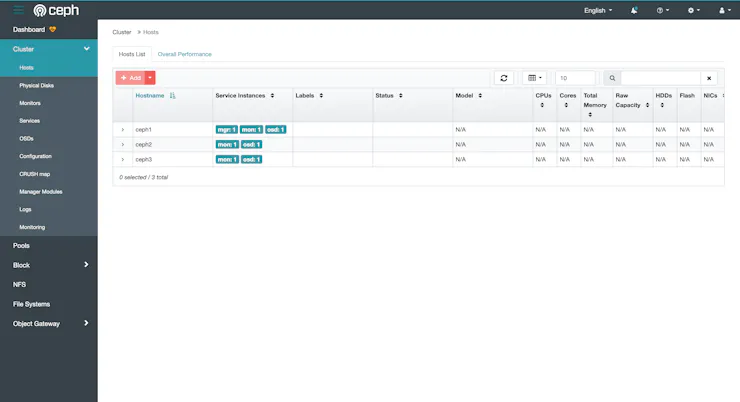
Der Screenshot vom Dashboard hebt die Präsenz von drei Metadata Servern hervor. Metadata Server sind verantwortlich für die Speicherung der Metadaten über die auf den OSDs gespeicherten Daten, was für die Clients notwendig ist, um auf ihre Daten im Cluster zuzugreifen und diese zu verwalten.
Als Nächstes werden wir zwei RADOS-Pools erstellen: einen Datenpool und einen Metadatenpool für das Ceph-Dateisystem, unter Verwendung der folgenden Befehle:
sudo ceph osd pool create cephfs_data 8
sudo ceph osd pool create cephfs_metadata 8
Die Angabe 8 spezifiziert die Anzahl der Placement Groups (PGs) für den Pool. Hier wird ein Wert von 8 zugewiesen, aber die optimale Anzahl von PGs kann je nach deinem spezifischen Cluster-Setup und der Arbeitslast variieren.
Erwartete Ausgabe:
pool 'cephfs_data' created
pool 'cephfs_metadata' created
Der Screenshot unten zeigt die Ceph-Speicherpools. Er hebt zwei neu erstellte Pools hervor.
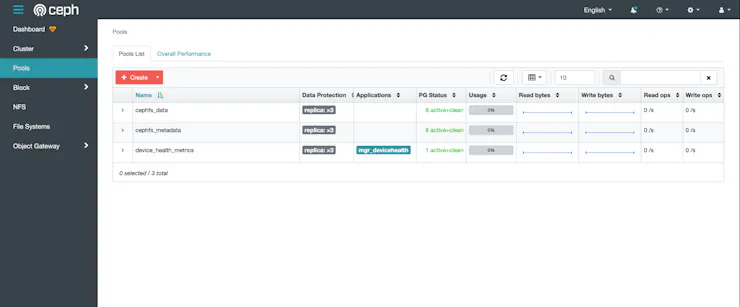
Nachdem die erforderlichen Pools erstellt wurden, werden wir das Ceph-Dateisystem mit dem folgenden Befehl erstellen:
sudo ceph fs new cephfs cephfs_metadata cephfs_dataDie erwartete Ausgabe für diesen Befehl sollte sein:
new fs with metadata pool 3 and data pool 2Verifiziere den Status mit CephFS und MDS nutze die folgenden Commands:
ceph mds stat
ceph fs ls
Die erwartete Ausgabe sollte sein:
cephfs:1 {0=ceph3=up:active} 2 up:standby<br>name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]<br>Stelle sicher, dass der MDS aktiv und in Betrieb ist, bevor du fortfährst.
Erstelle dann eine Geheimdatei für CephFS. Wir würden den folgenden Befehl ausführen, um aus dem Schlüssel eine Geheimdatei zu erstellen, die für die Authentifizierung zum Einbinden auf dem Client verwendet wird.
sudo ceph-authtool -p ./ceph.client.admin.keyring > ceph.key<br>Du kannst auch einen Benutzer-Schlüsselbund erstellen, den wir in beiden Lösungen für Autorisierung und Authentifizierung verwenden können, da wir cephx mit dem folgenden Befehl aktiviert haben.
sudo ceph auth get-or-create client.user mon 'allow r' mds 'allow r, allow rw path=/home/cephfs' osd 'allow rw pool=cephfs_data' -o /etc/ceph/ceph.client.user.keyring<br><br>
Schließlich kopieren wir die Geheimdatei und ceph.conf auf die Client-Maschine.
Mount CephFS mit Kernel Driver
CephFS bietet zwei Möglichkeiten, das Dateisystem einzubinden – über den Kernel oder den FUSE-Client.
Um CephFS mit dem Kernel-Treiber einzubinden, musst du das Ceph-Kernel-Client-Modul auf deinem System installiert haben. Verwende den folgenden Befehl, um CephFS mit dem Kernel-Treiber einzubinden:
sudo mount -t ceph <MONITOR_IP>:/<PATH> /mnt/cephfs -o name=<USERNAME>,secret=<SECRET_KEY>In meinem Fall führe ich aus:
mount -t ceph ceph1,ceph2,ceph3:/ /mnt/cephfs -o name=admin,secretfile=/etc/ceph/ceph.key,noatimeEinhängen erfolgreich. Um das Einhängen zu überprüfen, verwende den folgenden Befehl:
df -hDie Ausgabe sollte sein:
Filesystem Size Used Avail Use% Mounted on
tmpfs 380M 3.1M 376M 1% /run
/dev/mmcblk0p2 118G 15G 99G 13% /
tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/mmcblk0p1 253M 137M 116M 55% /boot/firmware
tmpfs 379M 4.0K 379M 1% /run/user/1000
192.168.0.106,192.168.0.107,192.168.0.108:/ 227G 0 227G 0% /mnt/cephfs
Um das Ceph-Dateisystem auszuhängen, verwende den folgenden Befehl:
umount /mnt/cephfsDieser Befehl hängt das Ceph-Dateisystem aus, das unter /mnt/cephfs eingehängt wurde.
Um das Ceph-Dateisystem beim Booten automatisch einzuhängen, bearbeite die fstab-Datei:
sudo nano /etc/fstab<br>Füge die folgende Konfiguration am Ende der Datei ein:
# CephFS Mount
ceph1,ceph2,ceph3:/ /mnt/cephfs ceph name=admin,secretfile=/etc/ceph/ceph.key,noatime 0 0
Speichere die Datei und verlasse den Nano-Editor.
Hänge alle Laufwerke aus der fstab mit dem Befehl mount -a ein, und liste dann alle verfügbaren Laufwerke auf:
sudo mount -aStarte abschließend das System neu.
Nach dem Neustart verwende df -hT, um zu bestätigen, dass das CephFS noch immer am vorgesehenen Ort eingehängt ist.
Starten und Stoppen aller Daemons
Um alle Ceph-Dienste auf einem bestimmten Knoten zu starten,
systemctl start ceph.targetUm alle Ceph-Dienste auf einem bestimmten Knoten zu stoppen,
systemctl stop ceph\*.service ceph\*.targetFazit und Ausblick
Das Bereitstellungstool ceph-deploy wurde zugunsten von cephadm für mehrere Ceph-Versionen eingestellt. Im Wesentlichen ist cephadm der moderne Ersatz für ceph-deploy. Im nächsten Tutorial werde ich demonstrieren, wie man einen Ceph-Speichercluster erweitert und das cephadm-Tool für die Bereitstellung und Wartung verwendet.
Shakhizat Nurgaliyev
In unserem neuesten Blogpost stellt Shakhizat Nurgaliyev , ein erfahrener Entwicklungsingenieur mit einer Passion für Robotik und IoT, seinen Einblick in die Erstellung eines Heim-Speicherclusters mit Raspberry Pi und Ceph vor. Seine Arbeit an autonomen Systemen und sein Engagement für maschinelles Lernen machen diesen Beitrag besonders wertvoll für Technikbegeisterte.
Möchtest du tiefer in die Welt des Heim-Speicherclusters mit Raspberry Pi und Ceph eintauchen und erfahren, wie du dein eigenes NAS mit einem Raspberry Pi aufbaust? Unser Blogpost bietet nicht nur eine gründliche Einführung in Ceph, sondern weist auch den Weg zu unserem detaillierten Leitfaden “NAS mit einem Raspberry Pi bauen – Eine Anleitung”, der dir zeigt, wie du Schritt für Schritt dein eigenes NAS-System realisieren kannst.