

Revolutionäre Technologie in der Barrierefreiheit durch KI, angetrieben durch ein Vision-Sprachmodell auf dem NVIDIA Jetson AGX Orin 64GB Kit. In unserer zunehmend vernetzten Welt, in der Daten und Technologie die Eckpfeiler des täglichen Lebens bilden, entstehen ständig neue Innovationen, die unsere Art zu leben und zu arbeiten revolutionieren. Zwei solcher bahnbrechenden Technologien, die generative künstliche Intelligenz (KI) und Edge Computing, stehen im Rampenlicht dieser Entwicklung. Diese Technologien sind nicht nur für sich genommen revolutionär, sondern entfalten ihr volles Potenzial erst, wenn sie zusammenarbeiten. In diesem Artikel werfen wir einen Blick auf die faszinierende Konvergenz von generativer KI und Edge Computing – eine Kombination, die die Grenzen dessen, was technologisch möglich ist, neu definiert und eine Zukunft einläutet, in der intelligente Systeme nahtlos und effizient am Rande unseres Netzwerks operieren.
- Die Rolle der Generativen KI und Edge Computing
- Generative KI-Anwendungen für Edge Computing
- NVIDIA Jetson AGX Orin 64GB Developer Kit
- MLC-LLM: Lokales Ausführen von quantisierten LLM-Modellen
- Hardware-Architektur
- Software-Architektur
- Die Hauptkomponenten des Systems sind:
- Ausführen der Vision2Audio-Webanwendung
- Einschränkungen
- Abschließende Worte
- Shakhizat Nurgaliyev
Die Rolle der Generativen KI und Edge Computing
Generative KI, eine Kategorie der künstlichen Intelligenz, hat die Fähigkeit, neue Texte, Bilder, Videos, Audiodateien oder Code zu erstellen. Diese Technologie steht vor der Herausforderung, mit der zunehmenden Komplexität und Vielfalt von Datenquellen – wie Bildern, Videos, Audio, Text, Sprache und Sensoren – umzugehen. Dies ist besonders relevant im Bereich des Edge Computings, einer Technologie, die die Datenverarbeitung an den Rand des Netzwerks verlagert, näher an die Datenquelle.
Die multimodale generative Künstliche Intelligenz stellt sich dieser Herausforderung, indem sie die gleichzeitige Verarbeitung verschiedener Datentypen ermöglicht. Während die meisten Anwendungen der generativen KI derzeit in der Cloud betrieben werden, untersuchen viele Experten nun die Rolle des Edge Computings bei der Unterstützung dieser Technologien. Edge Computing könnte entscheidend sein, um die Effizienz und Geschwindigkeit der Datenverarbeitung in generativen KI-Anwendungen zu verbessern, insbesondere in Umgebungen, in denen eine schnelle Datenverarbeitung erforderlich ist.
Generative KI-Anwendungen für Edge Computing
Die Kombination aus Edge Computing und generativer KI ermöglicht Echtzeit-Anwendungen der generativen KI. Aufgrund ihrer steigenden Beliebtheit erfordern generative KI-Anwendungen, dass einige oder alle KI-Arbeitslasten auf Edge-Geräte wie Smartphones, PCs und andere verlagert werden. Derzeit besteht eine wachsende Nachfrage nach dem Betrieb großer Sprachmodelle wie ChatGPT auf stromsparenden Einplatinencomputern für Offline- und Anwendungen mit geringer Latenz. Dieses Projekt zeigt dir, wie du eine von generativer KI angetriebene Anwendung auf dem NVIDIA Jetson AGX Orin Developer Kit entwickeln und bereitstellen kannst. Dieses Edge-Gerät wird aufgrund seiner Fähigkeit, das Inferencing des größten Llama-2-Modells mit 70 Milliarden Parametern zu betreiben, besonders empfohlen.


NVIDIA Jetson AGX Orin 64GB Developer Kit
In meinem vorherigen Projekt “Vision2Audio: Dem Blinden Verständnis durch KI geben” habe ich eine End-to-End-Webanwendung für Sehbehinderte und Blinde entwickelt, die llama.cpp und LLaVA (Large Language and Vision Assistant) nutzt. Llama.cpp ist eine von Georgi Gerganov entwickelte Bibliothek, die für effizientes Ausführen von LLMs (Large Language Models) auf CPUs/GPUs ausgelegt ist. Dort habe ich einige Einschränkungen erwähnt, die ich in diesem Projekt beheben möchte. Diese Webanwendung soll sehbehinderten und blinden Menschen die Möglichkeit geben, Bilder aufzunehmen und in Echtzeit Fragen zu stellen, indem sie die optimierte Technologie von MLC LLM und das lokale_llm(@Dustin Franklin)-Projekt nutzt, was eine schnellere Leistung als llama.cpp verspricht.
MLC LLM, kurz für Machine Learning Compilation für Large Language Models, ist ein Framework, das darauf abzielt, eine hohe Leistung und universelle Bereitstellung großer Sprachmodelle zu ermöglichen. Es nutzt Compiler-Beschleunigung, um die native Bereitstellung dieser Modelle mit nativen APIs über verschiedene Geräte hinweg, einschließlich Web, iOS und Android, zu ermöglichen und unterstützt mehrere Programmiersprachen und APIs.
MLC-LLM: Lokales Ausführen von quantisierten LLM-Modellen
MLC-LLM eröffnet uns die faszinierende Möglichkeit, quantisierte LLM-Modelle (Large Language Models) lokal auf ressourcenbeschränkten Geräten wie dem NVIDIA Jetson AGX Orin Einplatinencomputer zu betreiben.
Für diese Anleitung gehen wir davon aus, dass bereits alles installiert ist. Also, ohne weitere Umschweife, lass uns loslegen!
Hardware-Architektur
Die Nutzung von Mobiltelefonen ist zu einem unverzichtbaren Teil unseres täglichen Lebens geworden. Daher ist es entscheidend, dass unsere Technologie über Mobiltelefone aus der Ferne über öffentliche Netzwerke zugänglich ist. Da die gesamte Verarbeitung auf dem Nvidia Jetson AGX Orin Developer Kit stattfindet, das zu Hause lokalisiert und mit einem lokalen Netzwerk mit Internetzugang verbunden ist, ist es entscheidend, eine Lösung für den Fernzugriff auf Webanwendungen zu finden. Hier bietet sich OpenVPN als praktikable Lösung an.
OpenVPN ist ein Open-Source-Projekt für ein Virtuelles Privates Netzwerk (VPN), das sichere Verbindungen über das Internet mit einem benutzerdefinierten Sicherheitsprotokoll, das auf SSL/TLS basiert, ermöglicht. Ein Raspberry Pi eignet sich hervorragend für die Einrichtung eines OpenVPN-Servers, dank seiner einfachen Konfiguration. Eine beliebte Funktion ist die Möglichkeit, Server oder Dienste im entfernten Netzwerk zu erreichen, sodass Benutzer ihre iPhones oder andere Geräte sicher über VPN mit ihrem Heimnetzwerk verbinden können.
Hier ist ein kurzer Überblick über das Szenario, das ich erstellen möchte:

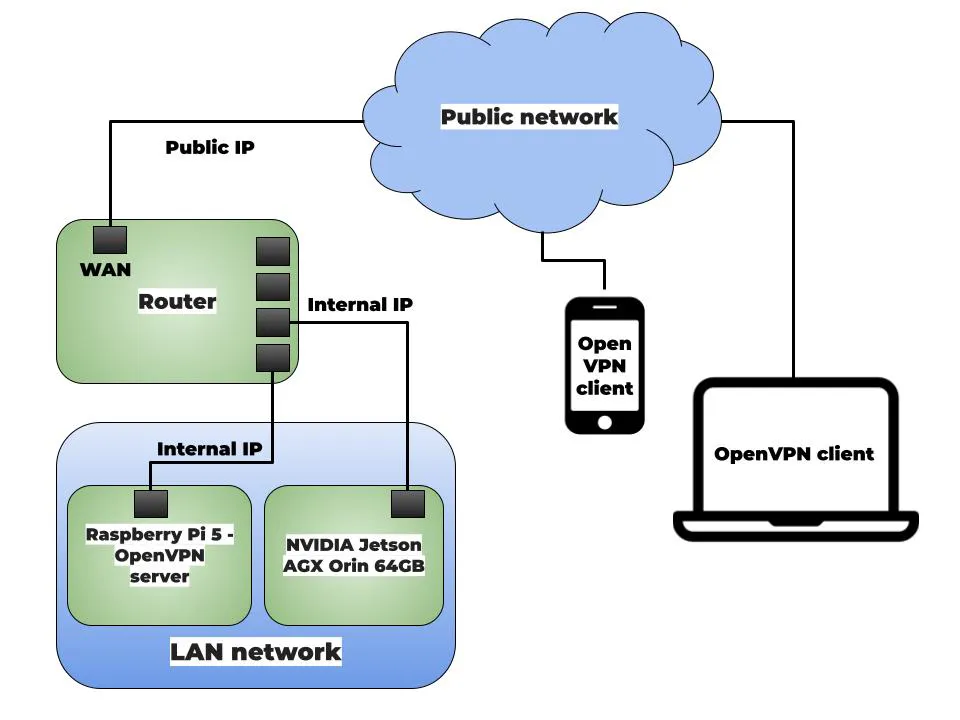
Das Diagramm zeigt ein lokales Netzwerk mit einem Router, einem Smartphone oder Computer sowie dem Nvidia Jetson AGX Orin Developer Kit. Der Router verfügt über zwei Schnittstellen: eine LAN-Schnittstelle und eine WAN-Schnittstelle. Die LAN-Schnittstellen sind mit dem Nvidia Jetson AGX Orin Developer Kit und dem Raspberry Pi verbunden. Die WAN-Schnittstelle ist mit dem Internet verbunden. Der Raspberry Pi fungiert als OpenVPN-Server, während das Smartphone oder der Computer als OpenVPN-Clients agieren.
Führe den folgenden Befehl aus, um PiVPN auf dem Raspberry Pi 5 zu installieren.
curl -L https://install.pivpn.io | bashDieser Befehl lädt das Installationsskript von der GitHub-Seite von PiVPN herunter und führt es aus. Anschließend erscheint ein Dialogfeld, in dem du einige Fragen zur Einrichtung des OpenVPN-Servers beantworten musst. In diesem Fall wählen wir die Standardeinstellungen, da sie ausreichen, um den Server in Betrieb zu nehmen.
Finde hier den Link zum gestützten Modell
Die Installation ist jetzt abgeschlossen! Starte deinen Raspberry Pi neu.
Nach dem Neustart führe den folgenden Befehl aus, um die Profilerstellung zu beginnen.
pivpn addWenn du die nachfolgenden Nachrichten siehst, war deine Installation erfolgreich.
::: Create a client ovpn profile, optional nopass<br>:::<br>::: Usage: pivpn <-a|add> [-n|--name <arg>] [-p|--password <arg>]|[nopass] [-d|--days <number>] [-b|--bitwarden] [-i|--iOS] [-o|--ovpn] [-h|--help]<br>:::<br>::: Commands:<br>::: [none] Interactive mode<br>::: nopass Create a client without a password<br>::: -n,--name Name for the Client (default: "raspberrypi")<br>::: -p,--password Password for the Client (no default)<br>::: -d,--days Expire the certificate after specified number of days (default: 1080)<br>::: -b,--bitwarden Create and save a client through Bitwarden<br>::: -i,--iOS Generate a certificate that leverages iOS keychain<br>::: -o,--ovpn Regenerate a .ovpn config file for an existing client<br>::: -h,--help Show this help dialog<br>Enter a Name for the Client: user<br>How many days should the certificate last? 1080<br>Enter the password for the client:<br>Enter the password again to verify:<br>* Notice:<br>Using Easy-RSA configuration from: /etc/openvpn/easy-rsa/pki/vars<br>* Notice:<br>Using SSL: openssl OpenSSL 3.0.11 19 Sep 2023 (Library: OpenSSL 3.0.11 19 Sep 2023)<br>-----<br>* Notice:<br>Keypair and certificate request completed. Your files are:<br>req: /etc/openvpn/easy-rsa/pki/reqs/user.req<br>key: /etc/openvpn/easy-rsa/pki/private/user.key<br>Using configuration from /etc/openvpn/easy-rsa/pki/14a25c96/temp.6c37cb45<br>Check that the request matches the signature<br>Signature ok<br>The Subject's Distinguished Name is as follows<br>commonName :ASN.1 12:'user'<br>Certificate is to be certified until Jan 10 22:23:31 2027 GMT (1080 days)<br>Write out database with 1 new entries<br>Database updated<br>* Notice:<br>Certificate created at: /etc/openvpn/easy-rsa/pki/issued/user.crt<br>Client's cert found: user.crt<br>Client's Private Key found: user.key<br>CA public Key found: ca.crt<br>tls Private Key found: ta.key<br>========================================================<br>Done! user.ovpn successfully created!<br>user.ovpn was copied to:<br>/home/raspi/ovpns<br>for easy transfer. Please use this profile only on one<br>device and create additional profiles for other devices.<br>========================================================references:Du kannst auf das Profil zugreifen, indem du zum Ordner ovpns navigierst. Lade dann die .ovpn-Datei in OpenVPN Connect. Der Client ist nun in der Lage, eine Verbindung zu deinem OpenVPN-Server herzustellen. OpenVPN hat einen offiziellen Client namens OpenVPN Connect, der auf Windows, macOS, Linux, iOS und Android verfügbar ist.
Sobald du dies tust, wird all dein Datenverkehr verschlüsselt und über deine Heiminternetverbindung geleitet, wo der Raspberry Pi sich befindet.
Du musst auch eine Portweiterleitung auf deinem Internetrouter einrichten. Der externe und interne Port sollte 1194 sein (dein benutzerdefinierter Port), und du solltest die IP-Adresse des Raspberry Pi im Feld für die IP-Adresse eintragen. Das Protokoll sollte UDP sein, und das ist alles. Die meisten Verbraucherrouter verfügen über eine Web-Admin-Oberfläche.
Wenn dein ISP CGNAT (Carrier-Grade NAT) verwendet, dann hast du keine öffentlich erreichbare IP-Adresse in deinem Heimnetzwerk. Dies schränkt leider die Möglichkeit ein, ein privates VPN zu betreiben, da du effektiv keinen direkten Zugang zum öffentlichen Internet hast. In diesem Fall kannst du entweder erforschen, was es braucht, um eine öffentlich routbare IP-Adresse von deinem ISP zu bekommen (manchmal bieten Geschäftspläne diese Funktion an) oder überlegen, einen Dienst wie den folgenden zu nutzen:
Dieser Dienst ermöglicht es dir, eine öffentlich zugängliche IP-Adresse oder Domain-Namen zu erwerben, die genutzt werden können, um auf deine lokalen Webdienste zuzugreifen. Bitte beachte, dass die Nutzung eines solchen Dienstes zusätzliche Kosten verursachen und möglicherweise deine persönlichen Daten gefährden kann.
Hier werden wir Cloudflare Tunnel verwenden, da es zuverlässiger und vertrauenswürdiger ist. Befolge diese Anweisungen, um cloudflared zu installieren. Du kannst die neueste Version von Cloudflared auf der Cloudflare-Website herunterladen.
Das Binary kannst du mit dem folgenden Befehl herunterladen:
wget https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-arm64.debSobald du das Binary heruntergeladen hast, kannst du es mit dem folgenden Befehl installieren:
sudo dpkg -i cloudflared-linux-arm64.debAnschließend kannst du einen Cloudflare Tunnel erstellen, indem du den folgenden Befehl ausführst:
cloudflared tunnel --url http://127.0.0.1:PORT_NUMBERDies wird deinen lokalen Server über den Cloudflare Tunnel verbinden.
Eine weitere Möglichkeit, einen Tunnel zu implementieren, ist die Verwendung eines SSH-Tunnels. Ein SSH-Tunnel verwendet das SSH-Protokoll, um einen sicheren Tunnel zwischen zwei Hosts zu erstellen.
Software-Architektur
Die Software-Architektur meiner Webanwendung Vision2Audio ist so konzipiert, dass sie Benutzerfreundlichkeit und Zugänglichkeit für alle Nutzer gewährleistet.
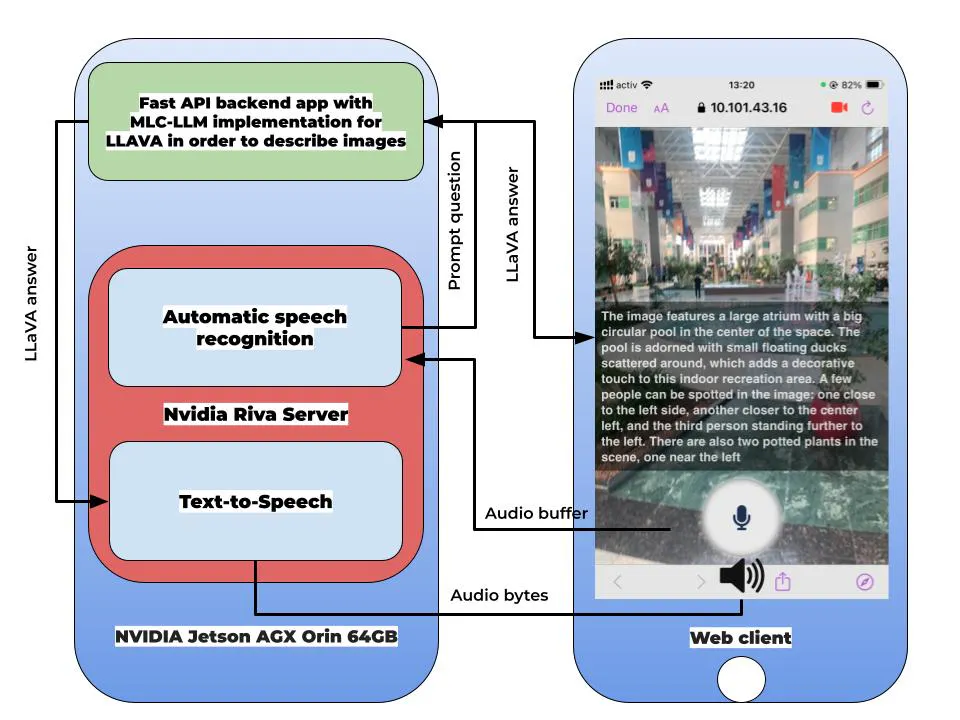
Die Hauptkomponenten des Systems sind:
- Fast API Backend-App: Die Backend-Anwendung ist mit Fast API und Python entwickelt und kombiniert die MLC-LLM-Implementierung des local_llm-Projekts von Dustin Franklin, um einen Bildverstehensdienst bereitzustellen. Der Frontend-Web-Client kommuniziert über REST-API-Anfragen mit der Fast API-Backend-Anwendung. Er sendet Anfragen an die Backend-API, um die Audioaufnahme zu initiieren, Transkriptionsergebnisse zu erhalten und Bilder für LLAVA zu senden.
- Frontend-Web-Client: Die Frontend-App ist so gestaltet, dass sie für Sehbehinderte und Blinde zugänglich ist. Sie nutzt die MediaRecorder-API in JavaScript für das Streaming von Audio und Video. Das aufgenommene Bild wird an die Fast API Backend-App weitergeleitet, um eine Bildbeschreibung zu generieren, während das aufgenommene Audio an das NVIDIA Riva Automatic Speech Recognition-System weitergeleitet wird. Howler.js wird verwendet, um Audio im Autoplay-Modus von NVIDIA Riva Text-to-Speech im Web-Client abzuspielen. Die Benutzeroberfläche ist benutzerfreundlich und für Sehbehinderte und Blinde konzipiert, sodass Benutzer sie mit nur einem Knopf steuern können.
- NVIDIA Riva Server: Diese Komponente dient als Spracherkennungs- und Text-zu-Sprache-Engine. Sie nimmt Audiodaten auf und konvertiert sie in Text und umgekehrt.
Ausführen der Vision2Audio-Webanwendung
Zum Schluss habe ich das Frontend unserer Webanwendung erstellt. Zuerst haben wir einen Ordner namens “templates” und “static” im selben Verzeichnis wie app.py angelegt.
Hier ist die resultierende Dateistruktur:
├── app.py<br>├── templates<br>│ └── index.html<br>├── static<br>│ └── howler.min.js<br>| └── microphone-solid.svg<br>| └── script.js<br>| └── style.cssStarte den Nvidia Riva Server, indem du den Befehl ausführst:
bash riva_start.shDu wirst folgende Ausgabe sehen:
Waiting for Riva server to load all models...retrying in 10 seconds<br>Waiting for Riva server to load all models...retrying in 10 seconds<br>Waiting for Riva server to load all models...retrying in 10 seconds<br>Waiting for Riva server to load all models...retrying in 10 seconds<br>Waiting for Riva server to load all models...retrying in 10 seconds<br>Waiting for Riva server to load all models...retrying in 10 seconds<br>Waiting for Riva server to load all models...retrying in 10 seconds<br>Waiting for Riva server to load all models...retrying in 10 seconds<br>Riva server is ready...<br>Use this container terminal to run applications:Sobald der Riva-Server läuft, öffne ein weiteres Terminal und führe den folgenden Befehl aus:
git clone https://github.com/dusty-nv/jetson-containers.gitIn diesem Projekt werden wir den vorgefertigten Docker-Container aus dem jetson-containers-Projekt verwenden. Es ist auch möglich, das Projekt aus der Quelle zu erstellen, aber das wird mehr Zeit in Anspruch nehmen.
./run.sh -v ./webapp:/app/ $(./autotag local_llm)Der Docker-Container wird automatisch gestartet und alle Dateien herunterladen. Dies kann je nach Netzwerkgeschwindigkeit 5 bis 20 Minuten dauern.
Innerhalb des Containers führe die folgenden Befehle aus:
pip3 install pydub <br>pip install python-multipart <br>sudo apt-get update <br>sudo apt-get install ffmpegBestimme die Größe des LLava-Modells, das du verwenden möchtest, wie beispielsweise 7B oder 13B für 7 Milliarden oder 13 Milliarden Parameter.
Führe abschließend den folgenden Befehl aus, um die Anwendung zu starten:
python3 -m uvicorn app:app --port 5000 --host 0.0.0.0 --ssl-keyfile ./key.pem --ssl-certfile ./cert.pemDieser Befehl wird die Anwendung auf Port 5000 starten und sie von außerhalb des Containers zugänglich machen.
INFO: Started server process [2215]<br>INFO: Waiting for application startup.<br>INFO: Application startup complete.<br>INFO: Uvicorn running on https://0.0.0.0:5000 (Press CTRL+C to quit)Beim ersten Start werden die Modellparameter in den lokalen Cache geladen, was einige Minuten dauern kann. Da die Einstellungen bereits im Cache gespeichert sind, werden spätere Neustarts und Aktualisierungen schneller erfolgen.
Richte dann die Kamera deines Handys auf das Bild, das du beschreiben möchtest. Die App wird dann ihre automatische Spracherkennung und Text-zu-Sprache-Fähigkeiten nutzen, um dir das Bild zu beschreiben.


Die meisten Browser auf iOS-Geräten haben eine Einschränkung, die verhindert, dass Audiodateien automatisch abgespielt werden, wenn eine Webseite geladen wird. Diese Einschränkung dient dazu, unerwünschte Audio-Wiedergabe ohne Zustimmung des Benutzers zu verhindern. Howler.js, eine in Vision2Audio verwendete JavaScript-Bibliothek, hat jedoch einen Weg gefunden, diese Einschränkung zu umgehen, indem sie benutzergesteuerte Ereignisse verwendet, um die Audiowiedergabe zu initiieren.
Klicke auf „Aufnahme starten“ und warte 5 Sekunden, bis sie beendet ist. Diese Funktion ist besonders nützlich für blinde Benutzer, die möglicherweise Schwierigkeiten haben, die Seite zu navigieren und den Stopp-Button zu finden. Die Anzahl der Schaltflächen auf der Seite wurde reduziert, um es sehbehinderten Benutzern zu erleichtern, die Audioaufnahmefunktion zu finden und zu bedienen. Die App wurde auf Varianten des iPhone 14 Pro Max, iPhone SE und Google Pixel getestet.
Die folgenden Beispiele veranschaulichen die Echtzeitnutzung von Vision2Audio.

Eines der Hauptmerkmale von Vision2Audio ist seine Fähigkeit zur Echtzeit-Erzählung. Dies ermöglicht es Benutzern, Audiodarstellungen ihrer Umgebung zu erhalten. Das kann besonders hilfreich sein, um sich in unbekannten Gegenden zu orientieren, da es den Nutzern wertvolle Informationen über ihre Umgebung liefert.
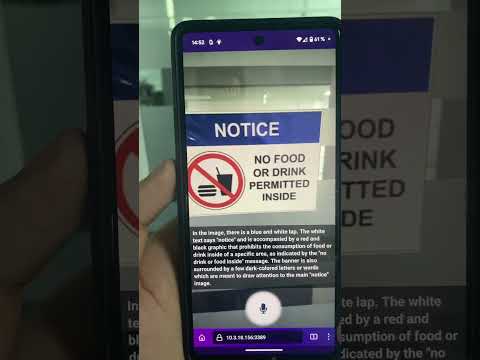
Ich konnte die Optical Character Recognition (OCR)-Fähigkeiten der Vision2Audio-Webanwendung testen.
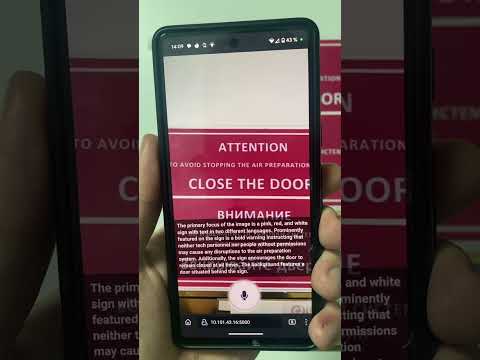
Die Fähigkeit der App, Text aus Bildern genau zu transkribieren, ist wirklich beeindruckend und eröffnet für Benutzer, die blind sind oder eine Sehschwäche haben, eine Welt voller Möglichkeiten.
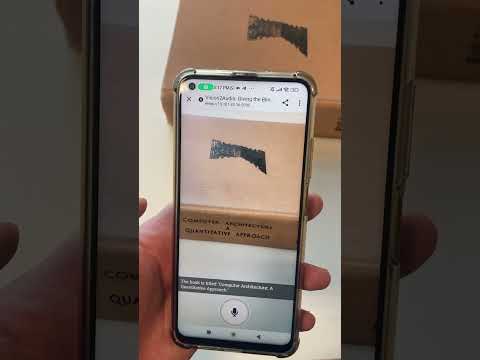
Diese Echtzeit-Erzählung versorgt die Nutzer mit wertvollen Informationen über ihre Umgebung, einschließlich der Position von Objekten, Menschen und Texten.
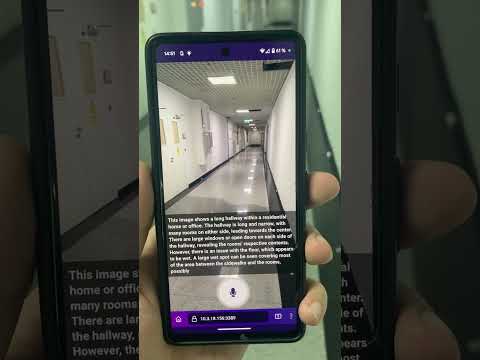
Wenn du unterwegs bist, kann Vision2Audio verwendet werden, um zu verstehen, wo du dich befindest und die Bilder um dich herum zu beschreiben. Dies kann dabei helfen, Hindernisse zu vermeiden und sich in unbekannten Gegenden zurechtzufinden. Das System kann dazu beitragen, Stürze und andere Unfälle zu verhindern.
Vision2Audio ist jedoch nicht nur auf die Navigation im Freien beschränkt. Es kann auch für alltägliche Aufgaben zu Hause unglaublich nützlich sein. Zum Beispiel kannst du es verwenden, um den Inhalt deines Kühlschranks zu beschreiben, was die Essensplanung erleichtert. Indem es die Lücke zwischen Wahrnehmung und Verständnis überbrückt, ermächtigt diese KI-Anwendung Benutzer, ihre Umgebung zu navigieren und sich wie nie zuvor mit der Welt um sie herum zu verbinden.
Insgesamt ist die Architektur der Vision2Audio-Technologie darauf ausgelegt, ein komfortables und zugängliches Erlebnis für alle Benutzer zu bieten, unabhängig von ihren Sehfähigkeiten. Indem sie die Kraft von Mobiltelefonen und fortschrittlichen multimodalen VLM (Vision Language Models) nutzt, zielt dieses Projekt darauf ab, diese Technologie zu einem wesentlichen Werkzeug für sehbehinderte und blinde Personen zu machen, um ihre Umgebung zu navigieren und mit der Welt um sie herum in Verbindung zu bleiben.
Einschränkungen
Halluzinierende Antworten: Das große Sprachmodell kann manchmal Antworten generieren, die ungenaue oder nicht unterstützte Informationen enthalten. Das bedeutet, dass VLMs (Vision Language Models) nicht garantiert 100% genaue Beschreibungen von Bildern liefern.
Netzwerklatenz: Dies kann als ein nicht-deterministischer Teil des Projekts betrachtet werden. Internetverbindungen können aufgrund verschiedener Umstände variieren.
Abschließende Worte
Mit diesem Leitfaden zur Entwicklung einer Assistenzanwendung für Sehbehinderte mithilfe der NVIDIA Jetson AGX Orin-Plattform hoffen wir, einen bedeutenden Beitrag zur Förderung der Barrierefreiheit durch KI zu leisten. Indem wir Technologie nutzen, um Hindernisse zu überwinden und den Zugang zu Informationen zu verbessern, können wir eine inklusivere Welt schaffen. Möge dieses Projekt dazu beitragen, das Leben von Menschen mit Sehbehinderungen zu erleichtern und ihre Teilhabe am digitalen Zeitalter zu fördern.
Shakhizat Nurgaliyev
Wir sind begeistert, dir heute einen spannenden Artikel präsentieren zu können, der uns von Shakhizat Nurgaliyev zur Verfügung gestellt wurde. Shakhizat ist ein leidenschaftlicher Entwicklungsingenieur für eingebettete Systeme mit einer beeindruckenden Expertise in den Bereichen Robotik und Internet der Dinge (IoT). Seine Spezialisierung liegt in der Entwicklung autonomer und intelligenter Systeme, die maschinelles Lernen nutzen, um auf ihre Umgebung zu reagieren. Von der Konzeption bis zur Programmierung bringt er umfangreiche Erfahrung mit, die maßgeblich zur Weiterentwicklung von Robotik und IoT beiträgt.